
데이터 중심 애플리케이션 설계 책을 읽으면서 정리한 내용입니다. 책 이외의 내용이 포함되어 있습니다.
다음은 데이터베이스를 운영하는 도중 발생할 수 있는 문제이다.
- 끄기 연산은 언제라도 실패할 수 있다.
- 연산중 데이터베이스가 종료될 수 있다.
- 네트워크에 문제가 생겨 데이터베이스 노드간 통신 문제가 생길 수 있다.
- 동시에 발생하는 쓰기 연산에 대해서 덮어쓸 수 있다.
- 부분 갱신으로 인해 클라이언트가 잘못된 데이터를 읽을 수 있다.
- race condition으로 인한 버그가 발생할 수 있다.
위와 같은 문제를 단순화 하고자 트랜잭션이 도입되었다. 트랜잭션은 읽기 쓰기 연산을 하나의 논리적 단위로 묶는 것이다.
트랜잭션 내부에 있는 모든 읽기, 쓰기는 하나의 논리적 단위이다.
트랜잭션은 전체가 성공하거나 실패한다.(원자성) → 오류 상황을 대처하기 쉬워진다.(오류 상황을 완전히 해결 할 수 있는 것은 아니다)
데이터베이스를 운영하면서 발생할 수 있는 문제점들을 살펴보고, 동시성 제어를 어떻게 해결할 수 있는지 살펴보자
또한 트랜잭션을 사용했을때, 특정 격리 수준을 채택했을때, 발생하는 trade-off 관계를 생각해보면 더 좋다!!

ACID
트랜잭션에서는 ACID를 만족해야 한다. 그러면 ACID중 하나라도 만족하지 못하면 트랜잭션이라고 할 수 없나?
→ 맞는 말이면서 틀린 말이다. 다양한 DB 제품들은 다양한 형태로 어떤 속성은 엄격하게, 느슨하게 ACID 원칙 두고 있다. 따라서 너무 엄격하게 생각하기 보다는 트랜잭션의 특성이라는 시각을 가지고 접근하는 것이 좋다.
원자성(atomicity)
더 이상 쪼갤 수 없다는 의미로 중간 상태를 가질 수 없다. 만약 트랜잭션이 아직 커밋(commit)되지 않고 실패(abort)된다면 해당 트랜잭션에 대한 연산이 모두 취소되야한다.
일관성(consistency)
항상 진실이어야 하는 데이터에 관한 선언이 있다는 것, 트랜잭션 실행 전과 후 모두 일관된 상태, 트랜잭션 내부에 있는 연산이 아닌 외부에서 선언된 제약조건(unique), 컬럼 조건이 트랜잭션이 실행되도 위배되지 않아야한다. (당연하게 느껴지는 속성이다)
관찰하게 어렵겠지만 트랜잭션 내부에서는 위배되고 무방하다(커밋시점에 일관하면 무방)
격리성(isolation)
실행중인 트랜잭션은 서로 격리되야 하며, 다른 트랜잭션을 방해 할 수 없다. 직렬성이라고 볼 수도 있겠다.

지속성(durability)
트랜잭션이 성공적으로 커밋되었다면 하드웨어에 결함 또는 소프트웨어가 중단 되더라도 데이터가 손실되지 않아야한다.
지속성을 보장하기 위해서 데이터베이스는 트랜잭션을 성공적으로 커밋됐다고 보고하기 전에 쓰기 복제에 대한 latency를 감수해야한다.
단일 객체 연산과 다중 객체 연산
다음 예시를 통해 원자성과 격리성이 필요한 이유를 이해할 수 있다.
db에 insert에 대해서 별도의 비정규화 과정을 위한 쿼리가 추가되는데 격리성을 보장하지 않는다고 가정한다.
이렇게 다중 객체 연산 상황으로 격리성이 보장 되지 않는 경우, 메세지를 잘못 읽을 수 있다.

원자성이 보장되지 않는 경우, 동기화 문제로 직결되어, 원자적 트랜잭션의 개수 갱신을 실패하면 트랜랙션이 abort 되고 삽입된 이메일은 롤백된다.
롤백 또한 격리성을 보장해야 한다.
다중 객체 트랜 잭션에서 연산에 대해서 동일한 트랜잭션에 속하는지 알아낼 수단이 있어야하는데, RDB의 경우 TCP connection 기반으로 식별한다.
https://dev.mysql.com/doc/refman/8.4/en/information-schema-innodb-trx-table.html
MySQL :: MySQL 8.4 Reference Manual :: 28.4.28 The INFORMATION_SCHEMA INNODB_TRX Table
28.4.28 The INFORMATION_SCHEMA INNODB_TRX Table The INNODB_TRX table provides information about every transaction currently executing inside InnoDB, including whether the transaction is waiting for a lock, when the transaction started, and the SQL stateme
dev.mysql.com
NoSQL의 경우 트랜잭션을 그룹화 할 수 있는 경우가 있다. 어느정도의 격리성을 위배를 감수하는 것이다. MongoDB의 경우, 롤백을 보장하고 있는 반면 Redis는 보장하지 않고 있다)
https://www.mongodb.com/ko-kr/docs/v5.0/core/transactions/
트랜잭션 - MongoDB 매뉴얼 v5.0
MongoDB 5.0 은(는) 2024 10월을 기준으로 수명이 종료됩니다. 이 버전의 문서는 더 이상 지원되지 않습니다. 5.0 배포서버 업그레이드 하려면 MongoDB.6 0 업그레이드 절차를 참조하세요.MongoDB에서 단일
www.mongodb.com
https://redis.io/docs/latest/develop/interact/transactions/
Transactions
How transactions work in Redis
redis.io
단일 객체 쓰기
단일 객체 연산에 대해서도 원자성과 격리성은 보장되어야한다.(네트워크, 시스템 에러)
스토리지 엔진들은 한 노드에 존재하는 단일 객체 수준에서 원자성과 격리성을 제공하는 것을 목표로 하고 있다. (원자성은 장애 복구 로그 활용, 격리성은 객체 Lock)
CAS와 같은 원자 연산을 제공하기도 한다.
다중 객체 트랜잭션의 필요성
분산 환경 데이터베이스에서는 다중 객체 트랜잭션 지원을 포기하는 경우가 적지 않다. (성능과 가용성을 위한 trade-off)
그럼에도 다중 객체 트랜잭션을 사용하는 경우가 있다.
- 외래키와 같은 제약조건
- 문서 데이터 모델
- secondary index
오류 Abort 처리
Abort 처리가 된다면 재시도 해야한다. ACID를 위반하는 위험이 있으면 트랜잭션을 도중에 페기한다.
예외적으로 리더 없는 복제의 경우, 취소하지 않는다고 한다.
대부분의 프레임워크들은 Abort에 대해 재시도하지 않는 것을 기본으로 가져간다.(Springboot의 hibernate) → Abort에 대한 원인을 클라이언트는 알지못한다. 따라서 실패원자성을 유지하는 보수적인 형태인 것이다.
완화된 격리 수준
트랜잭션은 결국 논리적 단위이다. 외부에서 ACID를 지키고 있는 것으로 관찰되면 내부적으로 어떻게 되면 무방하다. 그래서 사실 트랜잭션은 병렬적으로 실행된다. 데이터에 대한 소유권을 통해(락) 연산을 진행한다. 트랜잭션이 병렬로 실행되면서 동시성 문제가 발생한다. 결국 리소스에 대한 소유권(락)을 가지고 경쟁하게 되는데, 데이터베이스는 트랜잭션 격리를 통해 동시성이 없는 것처럼 느끼지길 기대하고 있다.
커밋 후 읽기
기본적인 수준의 트랜잭션 격리으로 다음 두가지를 보장한다.
- 읽기 연산에 커밋된 데이터를 사용한다
- 쓰기 연산에 커밋된 데이터 덮어쓴다.
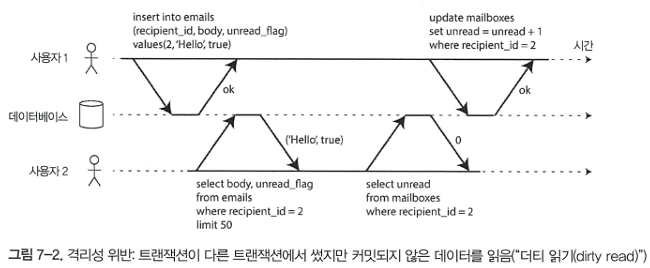
커밋되지 않은 데이터를 읽기, 쓰기 연산에 사용하지 않는 것을 더티 읽기, 쓰기 방지라고 한다.
여기서 더티란 아직 commit, abort 되지 않은 데이터 변경 내역이다.


로우 수준 잠금(Lock)을 사용해 더티 쓰기를 방지한다. Lock은 트랜잭션 commit, abort때까지 소유해야한다. (lock의 대상은 데이터 베이스 설정에 따라 달라진다. 가장 naive한 방법은 lock per table이다)
더티 읽기에 경우 동일한 방법을 적용할까? 적용해도 무방하지만 성능관점에서 효과적이지 않다. 따라서 아직 커밋되지 않은 데이터에 대해서는 커밋되기 이전 값을 읽는다.(그러면 커밋되지 않은 데이터, 즉 과거의 데이터를 관리해야한다)
스냅숏 격리와 반복읽기
커밋 후 읽기 정책을 통해 대다수의 동시성 문제를 해결할 수 있다. 그러나 다음 사진을 보자

아직 커밋 후 읽기 정책에 따라 두 계좌의 금액의 합이 올바르지않다.
이러한 비반복 읽기, 읽기 스큐라고 하는데, 지속적인 문제가 아니기 때문에 비일관성을 감수할 수 도 있다.
스냅숏 격리로 이 문제를 해결 할 수 있는데, 각 트랜잭션은 데이터베이스의 일관된 스냅숏을 읽는다. 따라서 트랜잭션을 통해 데이터에 대한 변경이 발생해도 다른 트랜잭션은 특정 과거 시점을 바라고 있기 때문에 일관성을 보장한다.
쉽게 말하면 스냅숏 격리는 데이터베이스에서 데이터에 대한 버전을 관리하겠다는 것이다. (커밋 후 읽기 정책은 커밋된 데이터에 대해서 관리하지 않는다. 믿고 사용할뿐)
스냅숏 격리를 위해 각 객체는 여러 버젼으로 관리되야하고, 이를 다중 버전 동시성 제어MVCC)라고 한다.

위 그럼은 postgrepl에서의 MVCC 기반 스냅숏 격리로 트랜잭션이 시작하면 계속 증가하는 고유한 트랜잭션 ID를 할당받아, 쓰기 연산에 대해서 트랜잭션 ID가 함계 붙는다
테이블의 각 로우에 해당 로우 쓰기 연산을 요청한 트랜잭션 ID를 갖는 created_by 필드가 있고, null 값을 가지는 deleted_by 필드가 있다.
해당 로우에 변경사항이 발생하면 deleted_by에 변경을 요청한 트랜잭션 ID 값으로 초기화되고, 새로운 로우에 created_by가 추가된다.
이와 같은 스냅숏 격리는 읽기 전용 트랜잭션에서 유용하다. 반복 읽기(repeatable read) 라고 한다. (스냅숏 격리와 반복 읽기를 같은 단어라고 이해해도 무방하다고 생각)
갱신 손실 방지
갱신 손실 문제란, 읽기 연산 + 변경 연산 과 변경 연산이 동시에 일어 났을때, 하나의 변경사항만 적용되는 문제이다. read-modify-write 문제라고 한다.
원자적 쓰기 연산을 사용하거나 명시적 잠금(EX Lock과 유사)을 사용하여 해결할 수 있다.
이러한 갱신 손실 방지법은 스냅숏 격리에 함계 사용했을때 효율성을 가진다.(왜 효율성을 가지는지는 크게 납득되지 않는다)
원자적 쓰기 연산중 하나인 CAS는 데이터의 최신 복사본이 하나만 있다고 가정한다. 다중 리더, 리더 없는 복제 환경에서 추가적인 동시성 문제를 고려해야 한다.
중간 요약
- 트랜잭션과 ACID
- 커밋 후 읽기
- 반복 읽기 (스냅숏 읽기)
- 경쟁 조건(더티쓰기와 갱신 손실)
앞내용과 앞으로 내용 모두 싱글 노드 환경임을 가정했을때 발생할 수 있는 동시성 문제이다.
쓰기 스큐와 팬텀
그런데 동시성 상황이 몇가지 더 있다.

약하면 true인 컬럼이 반드시 있어야 하는 비즈니스 로직에 대해서 동시에 false으로 변경하는 쿼리가 발생하였고, 스냅숏 격리에는 위반되지 않기 때문에 정상적으로 실행되어 true컬럼이 하나도 없는 상황이다. (쓰기 스큐)라고 한다.
쓰기 스큐는 데이터베이스가 비즈니스 로직을 알지 못하는 것에서 비롯된다.
쓰기 스큐를 해결하는 방법은 쿼리에 대한 결과에 대해 미치는 영향을 알려줄 수 있다면, 다른 하나의 쿼리의 결과를 실패로 반환할 수 있다.
2PL
2 Phase Lock은 더티쓰기에 사용되는 lock과 유사한데, 요구사항이 더 강하다. 쓰기 연산이 없는 객체에 대해서는 여러 트랜잭션의 읽기 연산을 허용한다. 그러나 변경 삭제에 대해서는 독점적이여야한다.
Shared Lock(공유 락, 읽기)
Exclusive Lock(베타 락, 쓰기)
2PL을 사용하면 격리 수준을 강화하는 것이기 때문에 성능을 감수해야한다.
서술 잠금(predicate lock)
- 트랜잭션 A가 SELECT * FROM users WHERE age > 30 실행 → id = 1, age = 35 조회됨.
- 트랜잭션 B가 INSERT INTO users (id, age) VALUES (2, 40); 실행 (새로운 행 삽입).
- 트랜잭션 A가 다시 SELECT * FROM users WHERE age > 30 실행 → id = 1, 2 두 개의 결과가 나옴.
위와 같은 팬텀 읽기 현상을 예방하기 위해 서술 잠금을 사용한다. 특정 where 조건에 대한 별도의 lock을 거는 것
그런데 서술 잠금은 잘 작동하지 않는다는 한다. 그래서 색인 범위 잠금, 다음 키 잠금와 같은 방법을 사용하기도 한다.

색인 범위 잠금은 인덱스 레벨에서 잠금을 구현하는 것이다.
정리
- 트랜잭션은 DB 연산의 단위이다.
- 트랜잭션은 ACID 원칙에 기반한다.(엄격하거나, 느슨하게 사용한다)
- 커밋 후 읽기 에서는 읽기 스큐가 발생할 수 있다.
- 스냅숏 읽기(반복 읽기)를 통해 읽기 스큐를 해결할 수 있다.
- 스냅숏 읽기(반복 읽기) 에서는 팬텀 읽기가 발생한다.
- 2PL으로 팬텀 읽기를 해결할 수 있다.
- 이외에도 더티 읽기, 더티 쓰기, 쓰기 스큐 등등…
실제 DBMS 사용예시
실제 DBMS에서 트랜젝션과 격리 수준을 어떻게 사용하는지 확인해보자
DBMS + Storage Engine 의 대부분의 내용을 생략했습니다.
MySQL
MySQL은 다음 4개의 트랜잭션 격리 수준을 채택하고 있다.
- SERIALIZABLE
- REPEATABLE READ (8.0 InnoDB 기준 기본값)
- READ COMMITTED
- READ UNCOMMITED
READ UNCOMMITED을 제외한 나머지 3개는 앞선 데이터 중심 책에서 나온 것들과 거이 동일하다. 위 방향을 갈 수 록 격리 수준이 강화된다.
SERIALIZABLE
책 설명과 동일하다. 2PL을 사용한다.
REPEATABLE READ
갱신 요청이 들어오면 갱신 이전 값을 undo log에 복사
commit해도 undo log를 바로 삭제하지 않는다. (예전에 실행되었지만 나중에 끝나는 트랜잭션이 있을 수 있음)
READ COMMITTED
REPEATABLE READ와 같이 undo log를 사용하는데 커밋되었다면 레코드를 확인
READ UNCOMMITTED
커밋되지 않더라도 데이터에 접근 가능
MongoDB
MongoDB 또한 MySQL과 동일한 격리 수준을 채택하고 있다.
- SERIALIZABLE
- REPEATABLE READ (8.0 InnoDB 기준 기본값)
- READ COMMITTED
- READ UNCOMMITED
mysql과 거이 동일하기 때문에 생락
mongoDB에서 스냅숏을 어떻게 관리하지는 확인되지 않음(WiredTiger의 MVCC에서 Write Ahead Logging (WAL)를 사용한다 정도)
Redis
redis는 앞선 데이터베이스와 성격이 다르다. 먼저 key-value 형식에 인메모리 db라는 것과 캐시 목적으로 사용되는 경우가 많다.
공식문서에 나와 있는 내용으로는
- 트랜잭션의 모든 명령은 직렬화되고 순차 실행된다. 다른 클라가 보낸 요청은 중간에 개입할 수 없고 격리성을 보장한다.
- EXEC command가 모든 command 실행을 트리거 한다. 만약 EXEC 실행전 클라이언트와 서버와의 연결이 끊어지면 어떤 작업도 수행되지 않는다.
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> INCR foo
QUEUED
127.0.0.1:6379> INCR bar
QUEUED
127.0.0.1:6379> exec
1) (integer) 1
2) (integer) 1
127.0.0.1:6379> keys *
1) "foo"
2) "bar"
127.0.0.1:6379>MULTI 블록 설정으로 트랜잭션을 정의할 수 있다.
연산들이 queueing되는 것을 확인 할 수 있다.(이때 읽기, 쓰기 연산이 모두 queueing된다)
만약 queueing 도중 오류가 발생하면 어떻게 할까 → 롤백하지 않고, 실행가능한 명령어는 실행한다.
정말 미미할정도의 기능을 하는 트랜잭션이다.
→ 롤백의 경우 Redis에서 단순성과 성능을 위해 포기했다고 한다.
>> WATCH KAROL
"OK"
>> SET KAROL 7
"OK"
>> MULTI
"OK"
>> SET KAROL 5
"QUEUED"
>> EXEC
(nil)
WATCH 명령어는 해당 key에 대한 변경이 외부에서 발생했을때 트랜잭션 내부에서 변경을 막는 연산이다. → 해당 데이터가 수정되지 않았을때 트랜잭션을 수행하도록하는 것이다. 앝은 잠금(Lock)이다.
요약하면
- Redis외부에서는 트랜잭션 없이 진행한다.
- MULTI 옵션을 통해 트랜잭션 block을 생성할 수 있다.
- 트랜잭션 block을 생성하는 것은 단일 사용자만 가능하다
- 트랜잭션에서 실패시 rollback없이 실행가능한 연산만을 수행한다.
- 따라서 하나의 트랜잭션에서 여러 키에 대한 원자성은 보장하지 못하지만, 단일 키에 대한 연산의 원자성은 보장한다.
'CS > 데이터베이스' 카테고리의 다른 글
| [MySQL] CLI환경에서 사용하기 (0) | 2024.05.20 |
|---|---|
| [Hadoop 완벽 가이드] Hadoop (1) | 2024.04.19 |
| [MYSQL] MySQL CLI 환경에서 실행하기 (0) | 2024.01.12 |