
이 포스팅은 공부목적으로 작성된 포스팅입니다. 왜곡된 정보가 포함되어 있을 수 있습니다.
Hadoop

Apache Hadoop
<!--- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or a
hadoop.apache.org
공식 문서에 따르면 하둡은 reliable, scalable, distribute computing을 위한 open-source 소프트웨어이다. reliable이 뭔데? scalable 이 뭔데? 각각은 분산 시스템의 특징들 인데, 아직 크게 이해되지 않는다면 분산 컴퓨팅을 제공하는 오픈소스라고 생각하자. 하둡을 사용하면 단순한 프로그래밍 만으로 컴퓨터 클러스터 대용량 데이터를 분산 처리할 수 있다.
미들웨어
하둡은 미들웨어이다. 미들웨어가 뭘까? 미들웨어는 middle+ware 으로 컴퓨터와 유저 사이에 존재하는 소프트웨어이다. 컴퓨터에게 친숙한 기계어와 인간에게 친숙한 C언어와 같은 고수준 언어 사이에 어셈블리어가 존재하는 것과 같이 중간 계층에 존재하는 것으로 이해할 수 있다. 그러면 미들웨어가 왜 필요할까? 아주 단순하게 생각하면 유저가 편하게 사용할 수 있기 때문이다. 분산 시스템 시점에서 보자면 유저로 하여금 유저는 미들웨어를 사용할 뿐이고, 하위 계층에 분산 환경에서 어떻게 프로세스가 진행되는지는 보여주지 않은 체로 마치 하나의 single computer와 같이 보이는 것이 미들웨어의 목표이자 분산시스템의 목표이다. 이러한 목표는 하둡의 소개에도 나왔듯이 reliable, scalable 또한 분산 시스템의 목표인 것이다! 아직 크게 이해되지 않는다면 미들웨어는 "사용자에게 편리하게 시스템을 사용할 수 있게 해주는 소프트웨어" 라고 생각하자!
빅데이터
왜 hadoop을 사용할까? 분산 환경에서 실행된다는 점을 미루어 볼때, "분산은 빠를 거 같은데?" 라는 생각을 해볼 수 있다. 틀린 말은 아니지만 hadoop을 사용하기 적절한 상황을 생각 해보자
단순히 hadoop을 사용하지 않는 엔지니어라고 생각해보았을때, 데이터를 관리하려면 엔지니어는 데이터베이스에 데이터를 관리한다고 생각할 것이다. 그러면 데이터가 빅데이터라면?
다음 3가지 요소를 가지게 되면 빅데이터라고 할 수 있다.
- volume: 데이터의 양이 많아야한다.
- velocity: 데이터를 빠르게 처리해야 한다.
- variety: 다양한 형태의 데이터가 존재한다.(데이터가 정제되어 있지 않다)
빅데이터의 예시로 생각해본다면 통계자료를 만들기 위해 지구 전체 인구를 대상으로 전수조사를 한 데이터를 통해 통계자료를 만들어야한다고 생각해보자. 기존의 데이터베이스를 사용할경우, 이러한 데용량 데이터를 빠르게 처리하기 위해 문제가 발생한다.
이러한 이유는 데이터베이스의 인덱싱 자료구조인 B+ tree를 생각해보면 이해할 수 있는데 input으로 들어오는 대용량 데이터에 대해서 b+tree 내부에서 수많은 insert과정이 발생한다. 또한 variety에 의해 알맞지 않은 format의 데이터가 들어올 수 있다 기존 데이터베이스는 데이터를 모두 관리하는 것을 목표로 하기 때문에 이에 대해 모두 처리를 해줘야 할 것이다. 그러나 실제 표본으로 통계자료를 만들때 극히 일부인 예외의 경우를 모두 꼼꼼하게 관리해야할까? 이러한 이유가 빅데이터는 기존 데이터베이스로 처리함에 옳지 못하다.
Hadoop의 기능
하둡은 빅데이터 처리를 위해 다음과 같은 기능을 제공한다.
- 병렬 연산
- 내결함성 분산 시스템 (하나의 시스템이 멈춰도 문제가 없도록)
- 내결함성 분산 저장소 (데이터가 지워지더라도 문제가 없도록)
- 손쉬운 단일 조작 시스템 (미들웨어)
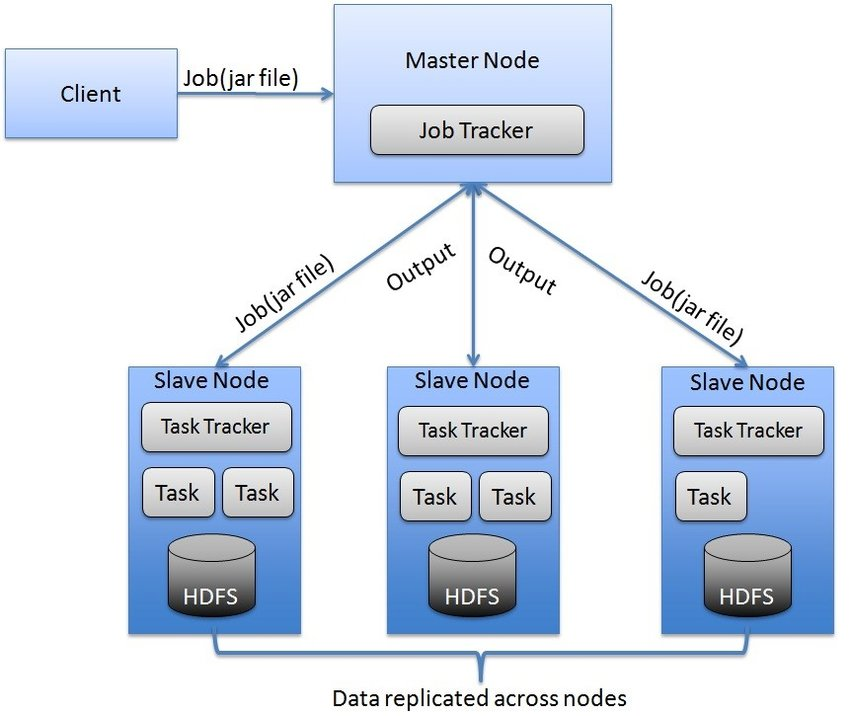
MapReduce을 통한 병렬 연산과 YARN을 통한 slave node들 간의 스케줄러 관리하고, HDFS(hadoop distributed file system)으로 내결함성 저장소 제공한다. 글쓴이도 아직 내부 동작 과정에 대해 알지 못하는데, 분산환경을 제어하는 nameNode(Master) 가 하위 dataNode(Slave)에게 작업을 배분하여 각각의 Slave에 작업을 수행한다고 이해하고 있다.
또한 각각의 작업에 대해서는 Master에서 Job Tracker와 Slave의 TaskTracker을 통해 전파된다고 이해했다.
'CS > 데이터베이스' 카테고리의 다른 글
| 트랜잭션 (0) | 2025.02.10 |
|---|---|
| [MySQL] CLI환경에서 사용하기 (0) | 2024.05.20 |
| [MYSQL] MySQL CLI 환경에서 실행하기 (0) | 2024.01.12 |
이 포스팅은 공부목적으로 작성된 포스팅입니다. 왜곡된 정보가 포함되어 있을 수 있습니다.
Hadoop
Apache Hadoop
<!--- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or a
hadoop.apache.org
공식 문서에 따르면 하둡은 reliable, scalable, distribute computing을 위한 open-source 소프트웨어이다. reliable이 뭔데? scalable 이 뭔데? 각각은 분산 시스템의 특징들 인데, 아직 크게 이해되지 않는다면 분산 컴퓨팅을 제공하는 오픈소스라고 생각하자. 하둡을 사용하면 단순한 프로그래밍 만으로 컴퓨터 클러스터 대용량 데이터를 분산 처리할 수 있다.
미들웨어
하둡은 미들웨어이다. 미들웨어가 뭘까? 미들웨어는 middle+ware 으로 컴퓨터와 유저 사이에 존재하는 소프트웨어이다. 컴퓨터에게 친숙한 기계어와 인간에게 친숙한 C언어와 같은 고수준 언어 사이에 어셈블리어가 존재하는 것과 같이 중간 계층에 존재하는 것으로 이해할 수 있다. 그러면 미들웨어가 왜 필요할까? 아주 단순하게 생각하면 유저가 편하게 사용할 수 있기 때문이다. 분산 시스템 시점에서 보자면 유저로 하여금 유저는 미들웨어를 사용할 뿐이고, 하위 계층에 분산 환경에서 어떻게 프로세스가 진행되는지는 보여주지 않은 체로 마치 하나의 single computer와 같이 보이는 것이 미들웨어의 목표이자 분산시스템의 목표이다. 이러한 목표는 하둡의 소개에도 나왔듯이 reliable, scalable 또한 분산 시스템의 목표인 것이다! 아직 크게 이해되지 않는다면 미들웨어는 "사용자에게 편리하게 시스템을 사용할 수 있게 해주는 소프트웨어" 라고 생각하자!
빅데이터
왜 hadoop을 사용할까? 분산 환경에서 실행된다는 점을 미루어 볼때, "분산은 빠를 거 같은데?" 라는 생각을 해볼 수 있다. 틀린 말은 아니지만 hadoop을 사용하기 적절한 상황을 생각 해보자
단순히 hadoop을 사용하지 않는 엔지니어라고 생각해보았을때, 데이터를 관리하려면 엔지니어는 데이터베이스에 데이터를 관리한다고 생각할 것이다. 그러면 데이터가 빅데이터라면?
다음 3가지 요소를 가지게 되면 빅데이터라고 할 수 있다.
- volume: 데이터의 양이 많아야한다.
- velocity: 데이터를 빠르게 처리해야 한다.
- variety: 다양한 형태의 데이터가 존재한다.(데이터가 정제되어 있지 않다)
빅데이터의 예시로 생각해본다면 통계자료를 만들기 위해 지구 전체 인구를 대상으로 전수조사를 한 데이터를 통해 통계자료를 만들어야한다고 생각해보자. 기존의 데이터베이스를 사용할경우, 이러한 데용량 데이터를 빠르게 처리하기 위해 문제가 발생한다.
이러한 이유는 데이터베이스의 인덱싱 자료구조인 B+ tree를 생각해보면 이해할 수 있는데 input으로 들어오는 대용량 데이터에 대해서 b+tree 내부에서 수많은 insert과정이 발생한다. 또한 variety에 의해 알맞지 않은 format의 데이터가 들어올 수 있다 기존 데이터베이스는 데이터를 모두 관리하는 것을 목표로 하기 때문에 이에 대해 모두 처리를 해줘야 할 것이다. 그러나 실제 표본으로 통계자료를 만들때 극히 일부인 예외의 경우를 모두 꼼꼼하게 관리해야할까? 이러한 이유가 빅데이터는 기존 데이터베이스로 처리함에 옳지 못하다.
Hadoop의 기능
하둡은 빅데이터 처리를 위해 다음과 같은 기능을 제공한다.
- 병렬 연산
- 내결함성 분산 시스템 (하나의 시스템이 멈춰도 문제가 없도록)
- 내결함성 분산 저장소 (데이터가 지워지더라도 문제가 없도록)
- 손쉬운 단일 조작 시스템 (미들웨어)
MapReduce을 통한 병렬 연산과 YARN을 통한 slave node들 간의 스케줄러 관리하고, HDFS(hadoop distributed file system)으로 내결함성 저장소 제공한다. 글쓴이도 아직 내부 동작 과정에 대해 알지 못하는데, 분산환경을 제어하는 nameNode(Master) 가 하위 dataNode(Slave)에게 작업을 배분하여 각각의 Slave에 작업을 수행한다고 이해하고 있다.
또한 각각의 작업에 대해서는 Master에서 Job Tracker와 Slave의 TaskTracker을 통해 전파된다고 이해했다.
'CS > 데이터베이스' 카테고리의 다른 글
| 트랜잭션 (0) | 2025.02.10 |
|---|---|
| [MySQL] CLI환경에서 사용하기 (0) | 2024.05.20 |
| [MYSQL] MySQL CLI 환경에서 실행하기 (0) | 2024.01.12 |