
이 블로그는 개인의 공부 목적으로 작성된 블로그입니다. 왜곡된 정보가 포함되어 있을 수 있습니다.
이전 포스팅에서 이어집니다~
[기계학습] Artificial Neural Network 1
이 블로그는 개인의 공부 목적으로 작성된 블로그입니다. 왜곡된 정보가 포함되어 있을 수 있습니다 0. beginning 몇년전, 알파고 부터 시작해서, 올해는 OpenAi의 ChatGPT와 같은 AI가 주목을 받고 있다
bluesparrow.tistory.com
1. Vanishing Gradient Problem
이전 포스팅에서는 역전파 알고리즘을 통해 기울기값을 조정한다는 것을 알아봤다.
그런데 미분하는데 발생하는 문제가 있는데 우리는 일반적으로 활성화 함수로 시그모이드 함수를 사용한다.
시그모이드 함수를 미분하면
$sigmoid(x)=\frac{1}{1+e^{-1}}$ 에서
$frac{d}{dx}sigmoid(x)=\frac{e^{-x}}{(1+e^{-x})^2}$
$=\frac{1}{1+e^{-x}}(1-\frac{1}{1+e^{-x}})$
$=sigmoid(x)(1-sigmoid(x))$ 이다.
이때 $0<sigmoid(x)<1$으로 $0<sigmoid(x)(1-sigmoid(x))<1$ 이다.
따라서 미분값 하면서 점점 미분값이 $0$에 수렴하게된다.
이는 노드들이 주는 영향이 점점 감소하게 되는것이고, 경사하강법에서 기울기가 감소하여 결국 변경할 기울기가 사라지는 현상을 말한다
2. Relu
$Relu(x)=max(0,x)$ 으로 vanishing gradient problem을 해결함
마지막 층을 제외한 층에서 활성화 함수로 사용
$0$ 이하의 경우 모두$0$을 가지기 때문에 Leaky Relu, Ramdomized Leaky Relu 와 같이 변형된 활성화 함수도 등장하였음
3. Regularization
4.Dropout
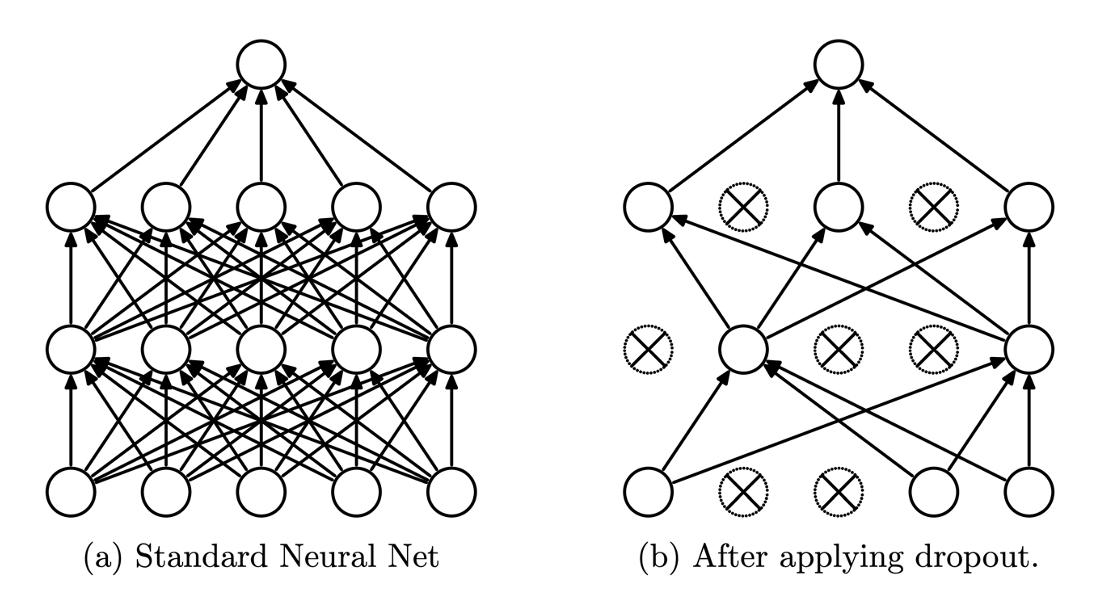
학습과정중에 지정된 비율만큼 간선을 끊어 성능을 개선하는 현상(기존 것 보다 일반화 능력 상승)
'AI > 기계학습' 카테고리의 다른 글
| [기계학습] CNN(Convolutional Network) (1) | 2023.12.09 |
|---|---|
| [기계학습] Artificial Neural Network 1 (1) | 2023.11.27 |
이 블로그는 개인의 공부 목적으로 작성된 블로그입니다. 왜곡된 정보가 포함되어 있을 수 있습니다.
이전 포스팅에서 이어집니다~
[기계학습] Artificial Neural Network 1
이 블로그는 개인의 공부 목적으로 작성된 블로그입니다. 왜곡된 정보가 포함되어 있을 수 있습니다 0. beginning 몇년전, 알파고 부터 시작해서, 올해는 OpenAi의 ChatGPT와 같은 AI가 주목을 받고 있다
bluesparrow.tistory.com
1. Vanishing Gradient Problem
이전 포스팅에서는 역전파 알고리즘을 통해 기울기값을 조정한다는 것을 알아봤다.
그런데 미분하는데 발생하는 문제가 있는데 우리는 일반적으로 활성화 함수로 시그모이드 함수를 사용한다.
시그모이드 함수를 미분하면
$sigmoid(x)=\frac{1}{1+e^{-1}}$ 에서
$frac{d}{dx}sigmoid(x)=\frac{e^{-x}}{(1+e^{-x})^2}$
$=\frac{1}{1+e^{-x}}(1-\frac{1}{1+e^{-x}})$
$=sigmoid(x)(1-sigmoid(x))$ 이다.
이때 $0<sigmoid(x)<1$으로 $0<sigmoid(x)(1-sigmoid(x))<1$ 이다.
따라서 미분값 하면서 점점 미분값이 $0$에 수렴하게된다.
이는 노드들이 주는 영향이 점점 감소하게 되는것이고, 경사하강법에서 기울기가 감소하여 결국 변경할 기울기가 사라지는 현상을 말한다
2. Relu
$Relu(x)=max(0,x)$ 으로 vanishing gradient problem을 해결함
마지막 층을 제외한 층에서 활성화 함수로 사용
$0$ 이하의 경우 모두$0$을 가지기 때문에 Leaky Relu, Ramdomized Leaky Relu 와 같이 변형된 활성화 함수도 등장하였음
3. Regularization
4.Dropout
학습과정중에 지정된 비율만큼 간선을 끊어 성능을 개선하는 현상(기존 것 보다 일반화 능력 상승)
'AI > 기계학습' 카테고리의 다른 글
| [기계학습] CNN(Convolutional Network) (1) | 2023.12.09 |
|---|---|
| [기계학습] Artificial Neural Network 1 (1) | 2023.11.27 |