
1. Instruction Set
명령어 집합(Instruction Set)으로 hardware의 처리를 추상화하는 계층이다.
컴퓨터마다 다른 IS를 가진다. 이 컴퓨터 구조 chapter는 MIPS에 기반한 컴퓨터 구조에 대한 내용이다.
MIPS instruction은 32bit로 구성되어있다.
2. Register
우리가 기본적으로 생각하고는 사칙연산들은 Register에서 일어난다. 데이터 처리 속도가 Register-Memory-Harddisk 순으로 속도가 빠르다. 나중에 왜 이러한 속도 차이가 나는지도 공부해보자.
Register에서 모든 연산이 일어나기 때문에 데이터가 Register에 있어서 한다.
그러나 Harddisk-Memory-Register 순으로 저장 공간이 많고 모든 데이터를 Register가 가지고 있을수 없다.
실제로 Register는 Register file의 형태로 관리되는데 하나의 Register file에 32개의 register 밖에 존재하지 않기 때문에 모든 데이터를 처리하기에대 상당히 부족하다.
따라서 우리는 데이터를 서로 다른 계층에서 전달하고 있는 연산도 필요하다.
3. big endian
MIPS는 낮은 주소의 데이터를 상위 비트부터 저장하고, 최상위 바이트 주소(MSB)를 워드주소로 사용하는 big endian방식을 사용한다. (역은 little endian(intel))
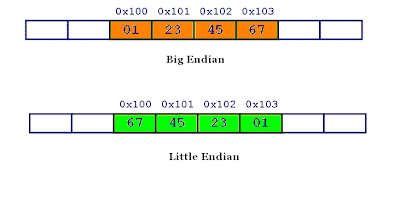
위 사진을 보면 우리가 저장하고자 하는 데이터는$ 01234567$이고, 상위 비트부터 저장되고, 워드 주소는 $0x100$ 이다.
여담으로 little endian, big endian에 대해 각각의 장단점이 있는데, 현대 컴퓨터에서는 거이 차이가 없도록 architecture를 설계했다고 한다.
MIPS에서 워드 시작주소는 반드시 4의 배수여야 하는 정렬 제약 원칙을 따르고 있는데, 이유는 나중에 알아보자(속도가 더 빠르다고 한다.)
sw, lw
메모리로 부터 데이터를 저장또는 로드하는 명령어이다.
$g=h+A[8]$ 을 lw를 사용해서 표현한다고 하면 $lw \ \ \$ t0, 8(\$ s3)$
MIPS에서 명령어의 길이는 32bits 이다. 명령어 타입은 R-format, I-format, J-format으로 총 3개이다.
R-format

op: opcode로 연산자를 정의한다.
rs: 첫번째 피연산자 레지스터
rt: 두번째 피연산자 레지스터
rd: 연산결과를 저장할 레지스터
shamt: shift 연산을 정의한다.
funct: 기능 즉 구체적인 연산을 정의한다(op와 funct에서의 연산이 다른 의미이고 서로 다른 역활을 함을 주의하자)
예시)
$add \ \$t0 \$s1 \ \$s2 $를 R-format MIPS instruction으로 바꿔 보자

먼저 register에 대해 살펴보면 register file의 32개의 register에 대해 R-format의 rs,rt,rd 가 5bit 배정되어 모든 register를 표현할 수 있다.
opcode는 이명령어가 R-format인지 결정해준다
shamt는 funct가 shift 명령인 sll, srl 의 경우에 사용되는데, $sll \ \$t2 \ \$s0, \ 4$ ( $\$s0$ 레지스터에 저장된 값을 왼쪽으로 4번 shift 한 결과값을 $\$t2$에 저장하는 연산)

rs 자리를 사용하지 않는 것을 확인 할 수 있을 것이다.(0)
그러면 왜 굳이 rs를 사용하지 않으면서까지 shamt를 통해 shift 연산을 구현했을까? (그냥 rs에 넣고 별도의 회로상 처리를 하면 안될까?)
<작성자의 개인 의견입니다 틀린부분이 발견되면 수정하겠습니다>
MIPS architecture의 원칙중 쉽게 설계하자는 원칙이 있다. 그리고 미리 datapath까지 공부한 나의 지식을 덧붙치지면, 실제로 MIPS에서 ARU에서 구현되는 연산이 add, or, and 와 같은 단순한 연산들만 정의되어 있고, 나머지는 컴파일러 측면에서 해석을 해줘야한다.(곱셈을 더하기로 표현하는것처럼) 그러나 shift를 아에 곱셈으로 분류하기에는 비트를 옮기면 되기 때문에 그다지 큰시간이 소요되지 않는다(해봐야 32+a번정도) 따로 별도의 처리를 넣으면 회로 구성이 복잡해지고, 그렇다고 아에 빼자니, 그렇게 느린 연산 까지는 아니기 때문에 별로로 분리해서 진행시키는 것으로 추측된다.(사실 이러한 회로는 이론적인 부분과 경험적인것(실제 소요시간) 두가지가 고려되기 때문에 이렇게 회로를 짜는게 더 빨라서 그냥 쓴다고 이해하는것도 나아보인다.
이어서 funct에서는 다양한 연산 종류가 정의된다(add,sub,sll,and,or등등)
회로 입장에서는 이게 variable 인지 Register 인지 알 방법이 없다. 그냥 이진수만 받기 때문에 우리가 하는 연산을 세부적으로 분리해야한다.
또한 MIPS는 not 연산대신 nor연산을 대신 사용하고 있다. nor 0은 not 동일하기 때문에 nor가 범용성이 더 높다.
I-format

constant fieid를 제외하고 나머지는 R-format가 동일하다.
constant field는 16bit으로 $2^{16}-1$까지 상수를 표현 할 수 있다.(unsigned의 경우)
sw,lw도 I-format이다.
그런데 범위를 벗어나는 상수 연산에 대해서는 어떻게 처리해야할까?
예를 들어 32bit 범위의 상수값을 레지스터에 저장하고 싶다면,
$ lui \$ to \ 1010101010101010 $ ($t0의 상위 16bit에 상수값저장)
$ ori \$ to \ \$ to \ 1010101010101010 $ ($t0에 상수값을 or연산한 값을 $t0에 저장)
Branch Instruction
조건 명령어도 I-format에 포함된다.
프로그래밍 언어에서 조건문은 조건이 참이면 조건문 아래를 실행하고 그렇지 않으면 조건문을 넘어서 실행된다.
MIPS에서는 살짝 다르게 조건 명령어가 존재하는데 $beq, \ bne$이 있다.
$beq register1, register, L1$ 의 형태로 사용되는데 register1,2의 값이 같다면 L1로 이동하겠다는 명령어 형태이다.
우리가 기존에 알던 복잡한 조건을 사용할 수 없다.(단순하게 구현해야하므로)
따라서 조건 처리 결과를 register1,2에 넣어서 $beq, \ bne$ 을 실행해야하고, 실제로 컴파일러도 그렇게 parse하고 있다,
그리고 branch instruction에서 constant field(위 예시에서 L1)는 $2^{15}$ 보다 더 넓은 범위를 표현할 수 있는데 명령어는 결국 word이기 때문에 4bytes 단위이기 때문에 15bit에 00의 2개의 bit가 추가되어 더 넓은 범위를 표현할 수 있다.
'CS > 컴퓨터구조' 카테고리의 다른 글
| 1. 성능(CPU TIME, CPI) (0) | 2023.07.06 |
|---|