[아워메뉴] ERD 설계 (엔티티 설계)
아워메뉴 프로젝트를 개발하면서 공부한 내용입니다.
아워메뉴를 다시 개발하면서 V1에서 고려하지 못했던 엔티티 설계를 다시 하였다. V1 에서 엔티티 설계를 잘못해서 프로젝트 중반에 예상하지 못한 문제를 많이 만나게 되었는데, 같은 실수를 반복하지 않기 위해 처음부터 다시 설계 하였다.
좋은 ERD, 좋은 엔티티
어떤 ERD를 좋다고 할 수 있을까?
데이터베이스 수업시간에 DB 설계와 관련하여 "정규화"라는 개념을 배우게 된다. "정규화"를 통해 관계형 데이터 베이스의 무결성을 보장하고, 용량을 줄일 수 있다.
그러나 우리가 실제로 만나는 ERD는 이론으로 배웠던 "정규화"와 다르다.
일단 실제로 우리가 구성하고자 하는 비즈니스 로직이 생각보다 복잡하다. 크게 문제가 되지 않는 경우 편의성을 위해서 반정규화 하는 사례도 적지 않다.
이외에도 프로그래밍 및 유지보수를 위해 다른 방법을 사용하기도 한다. (대표적으로 유일성을 보장하는 키에 대해서 PK으로 설정하지 않고, 별도의 PK 컬럼을 관례적으로 사용한다.)
V1 ERD
다음은 V1에 설계했던 erd이다.
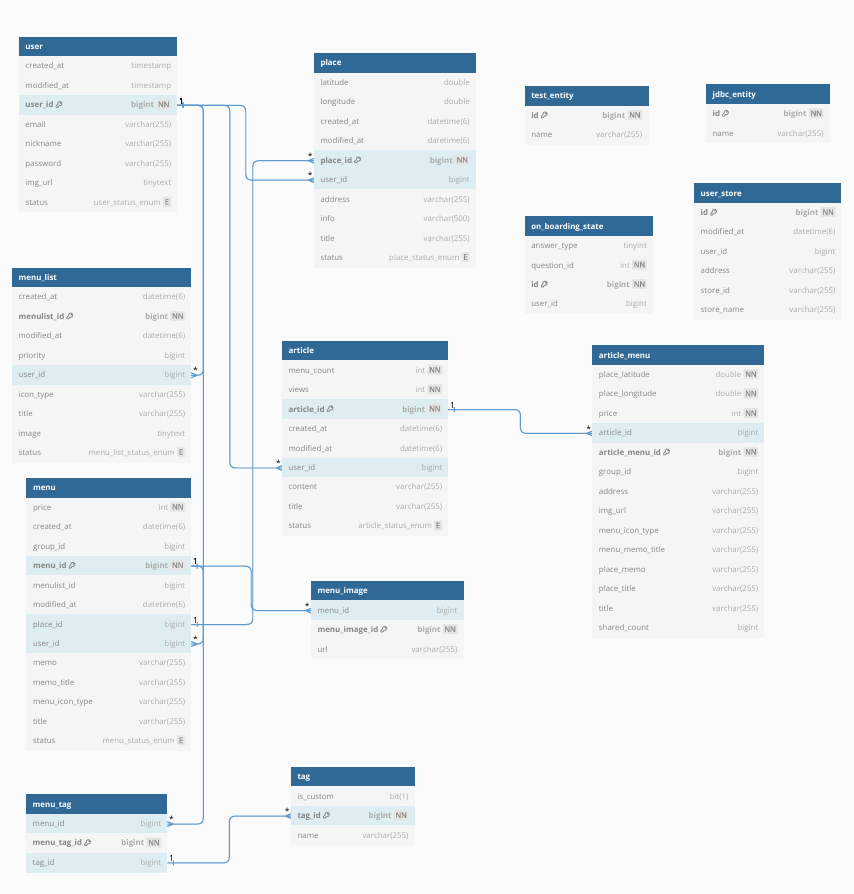
당시에 기억은 떠올려보면, 확장성이 높은 구조보다는 단기간에 프로젝트를 완성해야한다는 점에서, 변경이 일어나지 않는 큰 요구사항의 경우 해당 요구사항을 만족할 수 있는 범위내에서 최대한 단순하게 ERD를 설계했다. menu_list와 menu가 1대다인것을 보면 알 수 있듯이, 데이터관점에서 연관관계가 올바르지 않더라도 비즈니스로직 관점에서 올바른 ERD를 구성하였다. (그러나 이는 프로젝트 진행 도중, 큰 화근이 되었다)
다른 아쉬웠던 부분으로는 user_id를 거이 모든 table의 외래키로 제악조건이 추가되어서, user_id를 가질 필요없는 컬럼도 user_id를 가지고 있게 되었다.(개발중 변경할 수 없었던 문제를 위한 트러블 슈팅 방법으로 돌려막기 했었다)

따로 문서화하지 않았기 때문에 ERD를 잘못 해석하거나 이전에 작성한 의도를 이해하지 못하고, 팀원들과 다시 회의하고 토론하면서 시간을 잡아먹기도 하였다.
다시 설계한 V2 ERD
V2에서는 ERD을 처음부터 끝까지 다시 설계하였다.
문서화를 해보기로 했다. 회의에는 당연했던 내용도 1~2주가 지나면 처음부터 시작하기 일쑤였기 때문에 당연한 내용도 최대한 작성하고자 했다.

비즈니스 로직에 대해서 크게 문제되지 않는 범위 아래에서 최대한 단순하게 ERD를 설계하고자 하였다.
- 순환 참조가 절대로 발생하는 않는 형태
- 제 1 정규화를 만족하는 형태
- 제 2 정규화를 만족하는 형태 (만약 필요 이상으로 테이블이 증가하거나, 비즈니스 로직 관점에서 불필요한 조인이 수반 되면 타협)
- 다대다 지양 (유지보수의 어려움)
다시 작성한 ERD는 다음과 같다

테이블에도 알 수 있듯이 일부 테이블은 제2 정규화를 만족하지 않는다.(not_found_store, not_owned_menu_search, owned_menu_search) 해당 테이블은 단순 저장, 조회 이외의 기능을 하지 않기 때문에 테이블을 분리하지 않았다.
address를 분리하여 공통처리 하지 않고 하나의 컬럼에 받은 이유도 같은 이유이다.
다대다의 경우 지양하고자 하였지만, 1대다를 선택하는 경우, 전자보다 생성되는 컬럼갯수가 더 많다는 점에 다대다를 채택하고 최대한 코드레벨에서 관리하고자 하였다.
JPA에서 연관관계(컬럼 VS 엔티티)
JPA와 같은 ORM을 사용하게 되면 ERD를 설계하는 것 이외에도 해결해야하는 문제가 있다. JPA에서는 외래키를 해당 외래키의 주인 컬럼에 해당하는 엔티티 객체로 바인딩 된다.
그래서 외래키를 사용하기 위해서는 해당 외래키 주인 엔티티를 검색하는 비용을 감수해야한다.(해당 id값만을 사용하는 것도 마찬가지이다.)
결론부터 말하자면 다음과 같은 이유로 최대한 엔티티가 아닌 컬럼으로 관리하고자 하였다.
- 불필요한 쿼리를 최소화 위함
- 필요이상의 연관관계는 쿼리 예측을 어렵게 함
- ORM에서 엔티티를 Object 이전에 데이터 관점으로 바라보기 위함
- 추후 개발하면서 컬럼 -> 엔티티 보다 엔티티 -> 컬럼으로 변경하는 것이 더 수월하다고 판단 했음
- 다양한 쿼리를 직접 작성하기 위함
이유에도 나와 있듯이 성능, 유지보수 관점보다는 성장하기에 도움이 되기 위한 방법을 선택했다고 할 수 있다. 요새 개발 공부를 하면서 "내가 DB를 능숙하게 다루지도 못하는데 JPA를 사용하는게 맞을까?" 라는 생각이 많았다.
"추상화된 ORM를 그래서 만든거 아니야?" 라고 말하면 할말이 없긴 하지만, 프로젝트 보다 학습 목적에서 이러한 선택을 하게 되었다.
다음과 같은 규칙을 정했다
- 외래키는 컬럼 값으로 가져가는 것을 기본으로 한다
- 만약 생명주기 같은 경우, 연관관계를 엔티티로 관리한다.
- 엔티티로 관리되는 연관관계에 대해서, 반드시 필요한 경우, 양방향 연관관계를 세워도 무방하다.
연관관계 역시, 비즈니스 로직과 연결되어 있기 때문에, 비즈니스 로직 관점에서 바라보았다.

완성된 엔티티들은 엔티티 연관관계 및 양방향 연관관계가 거이 없는 형태가 되었다.(개발하면서 일부 연관관계가 추가되었다)
다음은 실제 작성한 엔티티의 일부로 Store는 엔티티로 연관관계를 가지지만 user_id는 엔티티가 아닌 값을 관리하고 있다.
@Entity
public class Menu extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotNull
private String title;
@NotNull
private Integer price;
private Boolean isCrawled;
@NotNull
private Long userId;
@ManyToOne(fetch = FetchType.LAZY)
private Store store;
}
확실히 연관관계에 대한 규칙을 정해놓았기 때문에, 실제 개발할 때 이점을 느낄 수 있었다. 연관관계가 있다면 반드시 사용해야 하기 때문에 크게 고민하지 않고, Join 하였다.
이렇게 설계를 마쳤다. 항상 직접 개발 해보면, 설계에서 예상했던것 이외의 문제를 만나게된다. 다음은 실제 개발하면서 만난 이슈들이다.
외래키에서의 N+1
엔티티가 아닌 값으로 외래키를 사용하면 네이티브 쿼리를 작성하기 때문에, N+1 문제를 어느정도 예방할 수 있다고 생각했다. 보통 N+1은 쿼리에 대한 인식 없이 개발하면서 발생했기 때문이다. (내 경험은 그렇다)
그런데 실제로 개발하면서 N+1을 만나게 되었다.
다음 코드이다.
@Query(value = """
SELECT m.id AS menuId, m.title AS menuTitle, s.title AS storeTitle, s.address
AS storeAddress, m.price AS menuPrice, m.created_at AS createdAt
FROM menu m
JOIN menu_tag mt ON m.id = mt.menu_id
JOIN store s ON m.store_id = s.id
WHERE mt.tag IN (:tags)
AND m.price BETWEEN COALESCE(:minPrice, 0)
AND COALESCE(:maxPrice, 2147483647)
AND m.user_id = :userId
GROUP BY m.id
HAVING COUNT(DISTINCT mt.tag) = :tagSize
ORDER BY m.title ASC
""",
countQuery = """
SELECT COUNT(*)
FROM (
SELECT m.id
FROM menu m
JOIN menu_tag mt ON m.id = mt.menu_id
WHERE mt.tag IN (:tags)
AND m.price BETWEEN COALESCE(:minPrice, 0)
AND COALESCE(:maxPrice, 2147483647)
AND m.user_id = :userId
GROUP BY m.id
HAVING COUNT(DISTINCT mt.tag) = :tagSize
) AS subquery
""", nativeQuery = true)
List<MenuSimpleDto> findByTagNameAndPriceRangeOrderByTitleAsc(
@Param("userId") Long userId,
@Param("tags") List<String> tags,
@Param("tagSize") Long tagSize,
@Param("minPrice") Long minPrice,
@Param("maxPrice") Long maxPrice,
Pageable pageable
);
조인과 페이징을 함께 하기 위한 쿼리이다. 쿼리양이 적지 않다.
/**
* 유저 메뉴 전체 조회 tag가 있는 경우
*
* @param userId
* @param menuFilterDto
* @return
*/
private List<GetSimpleMenuResponse> findMenusByTagsAndPricePageAndSort(Long userId, MenuFilterDto menuFilterDto) {
List<MenuSimpleDto> menuSimpleDtos = new ArrayList<>();
SortOrder sortOrder = menuFilterDto.getSortOrder();
List<String> tags = menuFilterDto.getTags().stream()
.map(Tag::getTagEnum)
.toList();
Long size = (long) tags.size();
// 중략
if (sortOrder.equals(SortOrder.PRICE_ASC)) {
menuSimpleDtos.addAll(menuRepository.findByTagNameAndPriceRangeOrderByPriceAsc(userId, tags, size,
menuFilterDto.getMinPrice(), menuFilterDto.getMaxPrice(), menuFilterDto.getPageable()
));
}
return menuSimpleDtos.stream()
.map(menuSimpleDto -> {
String imgUrl = menuImgService.findUniqueImg(menuSimpleDto.getMenuId());
return GetSimpleMenuResponse.of(menuSimpleDto, imgUrl);
}
).toList();
}
해당 쿼리를 사용하는 로직으로 후반부에 스트림을 통해 각 컬럼에 대한 이미지 값을 가져오는 것을 확인할 수 있고, N+1 문제가 발생함을 확인할 수 있다. 엔티티 매니저의 권한을 벗어난 영역이기 때문에 N+1의 대처 방법중 하나인 batch size를 적숑할 수 도 없다
쿼리에 한번에 처리하면 문제가 해결할 수 있는데, 해당 이미지 값을 가져오는 쿼리도 단순 조회는 아니라는 점에서 쿼리의 양이 더 늘어날 것으로 보인다.
쿼리의 길이에 대해서는 크게 상관 없다는 의견이였지만, "유지보수를 할 수 있는 코드라고 할 수 있을까?" 라는 질문에 완전히 찬성하기는 어렵다.
Native Query에서 Order By
유지보수와 관해서도 한가지 이슈가 더 있었다. 정렬 처리를 위해 정렬 컬럼 및 조건을 매개변수로 처리하고자 하였다. 그런데 Native Query에서는 SQL 칼럼명, 테이블명, 키워드에 값을 바인딩할 수 없어서 정렬을 동적을 처리할 수 없다.
그래서 다음과 같은 코드가 나왔다.
@Query(value = """
SELECT m.id AS menuId, m.title AS menuTitle, s.title AS storeTitle, s.address
AS storeAddress, m.price AS menuPrice, m.created_at AS createdAt
FROM menu m
JOIN menu_tag mt ON m.id = mt.menu_id
JOIN store s ON m.store_id = s.id
WHERE mt.tag IN (:tags)
AND m.price BETWEEN COALESCE(:minPrice, 0)
AND COALESCE(:maxPrice, 2147483647)
AND m.user_id = :userId
GROUP BY m.id
HAVING COUNT(DISTINCT mt.tag) = :tagSize
ORDER BY m.title ASC
""",
countQuery = """
SELECT COUNT(*)
FROM (
SELECT m.id
FROM menu m
JOIN menu_tag mt ON m.id = mt.menu_id
WHERE mt.tag IN (:tags)
AND m.price BETWEEN COALESCE(:minPrice, 0)
AND COALESCE(:maxPrice, 2147483647)
AND m.user_id = :userId
GROUP BY m.id
HAVING COUNT(DISTINCT mt.tag) = :tagSize
) AS subquery
""", nativeQuery = true)
List<MenuSimpleDto> findByTagNameAndPriceRangeOrderByTitleAsc(
@Param("userId") Long userId,
@Param("tags") List<String> tags,
@Param("tagSize") Long tagSize,
@Param("minPrice") Long minPrice,
@Param("maxPrice") Long maxPrice,
Pageable pageable
);
//중략
List<MenuSimpleDto> findByTagNameAndPriceRangeOrderByCreatedByDesc(
@Param("userId") Long userId,
@Param("tags") List<String> tags,
@Param("tagSize") Long tagSize,
@Param("minPrice") Long minPrice,
@Param("maxPrice") Long maxPrice,
Pageable pageable
);
//중략
List<MenuSimpleDto> findByTagNameAndPriceRangeOrderByPriceAsc(
@Param("userId") Long userId,
@Param("tags") List<String> tags,
@Param("tagSize") Long tagSize,
@Param("minPrice") Long minPrice,
@Param("maxPrice") Long maxPrice,
Pageable pageable
);
중략했지면 메소드 3개에 대한 코드길이가 100줄이나 된다.
확인된 방법중 유지보수를 위해 할 수 있는 방법은 동적으로 Native query를 생성해야하는 그것 마저도 case으로 쿼리를 분기해야되서 다른 방법을 모색하고 있다.

개발을 진행하면서, 새로운 설계한 엔티티에 따른 이슈가 생기고 있지만, 좋은 공부 기회로 만들고 싶다.